上篇博客介绍了JavaScript正则表达式的语法,有了这些基本知识,可以看看正则表达式在JavaScript的应用了,在一切开始之前,看看RegExp实例的几个属性
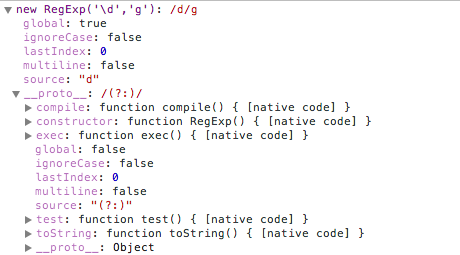
RegExp实例对象有五个属性
- global:是否全局搜索,默认是false
- ignoreCase:是否大小写敏感,默认是false
- multiline:多行搜索,默认值是false
- lastIndex:是当前表达式模式首次匹配内容中最后一个字符的下一个位置,每次正则表达式成功匹配时,lastIndex属性值都会随之改变。
- source:正则表达式的文本字符串
除了将正则表达式编译为内部格式从而使执行更快的compile()方法,对象还有两个我们常用的方法
regObj.test(strObj)
方法用于测试字符串参数中是否存正则表达式模式,如果存在则返回true,否则返回false
var reg=/\d+\.\d{1,2}$/g;reg.test('123.45'); //truereg.test('0.2'); //truereg.test('a.34'); //falsereg.test('34.5678'); //false regObj.exec(strObj)
方法用于正则表达式模式在字符串中运行查找,如果 exec() 找到了匹配的文本,则返回一个结果数组。否则,返回 null。除了数组元素和 length 属性之外,exec() 方法还返回两个属性。index 属性声明的是匹配文本的第一个字符的位置。input 属性则存放的是被检索的字符串 string。
调用非全局的 RegExp对象的 exec() 时,返回数组的第 0 个元素是与正则表达式相匹配的文本,第 1 个元素是与 RegExpObject 的第 1 个子表达式相匹配的文本(如果有的话),第 2 个元素是与 RegExp对象的第 2 个子表达式相匹配的文本(如果有的话),以此类推。
调用全局的RegExp对象的 exec() 时,它会在 RegExp实例的 lastIndex 属性指定的字符处开始检索字符串 string。当 exec() 找到了与表达式相匹配的文本时,在匹配后,它将把 RegExp实例的 lastIndex 属性设置为匹配文本的最后一个字符的下一个位置。可以通过反复调用 exec() 方法来遍历字符串中的所有匹配文本。当 exec() 再也找不到匹配的文本时,它将返回 null,并把 lastIndex 属性重置为 0。
var reg=/\d/g;var r=reg.exec('a1b2c3'); console.log(reg.lastIndex); //2r=reg.exec('a1b2c3');console.log(reg.lastIndex); //4 两次执行r的结果
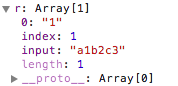

var reg=/\d/g;while(r=reg.exec('a1b2c3')){ console.log(r.index+':'+r[0]);} strObj.match(RegObj)
match() 方法将检索字符串 stringObject,以找到一个或多个与 regexp 匹配的文本。但regexp是否具有标志 g对结果影响很大。
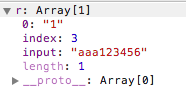
如果 regexp 没有标志 g,那么 match() 方法就只能在 strObj 中执行一次匹配。如果没有找到任何匹配的文本, match() 将返回 null。否则,它将返回一个数组,其中存放了与它找到的匹配文本有关的信息。该数组的第 0 个元素存放的是匹配文本,而其余的元素存放的是与正则表达式的子表达式匹配的文本。除了这些常规的数组元素之外,返回的数组还含有两个对象属性。index 属性声明的是匹配文本的起始字符在 stringObject 中的位置,input 属性声明的是对 stringObject 的引用。
var r='aaa123456'.match(/\d/);
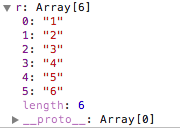
如果 regexp 具有标志 g,则 match() 方法将执行全局检索,找到 strObj 中的所有匹配子字符串。若没有找到任何匹配的子串,则返回 null。如果找到了一个或多个匹配子串,则返回一个数组。不过全局匹配返回的数组的内容与前者大不相同,它的数组元素中存放的是 strObj 中所有的匹配子串,而且也没有 index 属性或 input 属性。
var r='aaa123456'.match(/\d/g);
strObj.replace(regObj,replaceStr)
关于strng对象的replace方法,我们最常用的时传入两个字符串的做法,但这种做法有个缺陷,只能replace一次
'abcabcabc'.replace('bc','X'); //aXabcabc replace方法的第一个参数还可以传入RegExp对象,传入正则表达式可以时replace方法更加强大灵活
'abcabcabc'.replace(/bc/g,'X'); //aXaXaX'abcaBcabC'.replace(/bc/gi,'X'); //aXaXaX
如果replace方法的第一个参数传入的是带分组的正则表达式,我们在第二个参数中可以使用$1...$9来获取相应分组内容,比如希望把字符串 1<%2%>34<%567%>89 的<%x%>换为$#x#$,我们可以这样
'1<%2%>34<%567%>89'.replace(/<%(\d+)%>/g,'@#$1#@');//"1@#2#@34@#567#@89"
当然还有很多方式可以达到这一目的,这里只是演示一下利用分组内容,我们在第二个参数中使用 @#$1#@,其中$1表示被捕获的分组内容,在一些js模板函数中可以经常见到这种方式替换字符串。
strObj.replace(regObj,function(){})
可以通过修改replace方法的第二个参数,使replace更加强大,在前面的介绍中,只能把所有匹配替换为固定内容,但如果我希望把一个字符串中所有数字,都用小括号包起来该怎么弄
'2398rufdjg9w45hgiuerhg83ghvif'.replace(/\d+/g,function(r){ return '('+r+')';}); //"(2398)rufdjg(9)w(45)hgiuerhg(83)ghvif" 把replace方法的第二个参数传入一个function,这个function会在每次匹配替换的时候调用,算是个每次替换的回调函数,我们使用了回调函数的第一个参数,也就是匹配内容,其实回调函数一共有四个参数
- 第一个参数很简单,是匹配字符串
- 第二个参数是正则表达式分组内容,没有分组则没有该参数
- 第三个参数是匹配项在字符串中的index
- 第四个参数则是原字符串
'2398rufdjg9w45hgiuerhg83ghvif'.replace(/\d+/g,function(a,b,c){ console.log(a+'\t'+b+'\t'+c); return '('+a+')';}); 2398 0 2398rufdjg9w45hgiuerhg83ghvif9 10 2398rufdjg9w45hgiuerhg83ghvif45 12 2398rufdjg9w45hgiuerhg83ghvif83 22 2398rufdjg9w45hgiuerhg83ghvif 这是没有分组的情况,打印出来的分别是 匹配内容、匹配项index和原字符串,看个有分组的例子,如果我们希望把一个字符串的<%%>外壳去掉,<%1%><%2%><%3%> 变成123
'<%1%><%2%><%3%>'.replace(/<%([^%>]+)%>/g,function(a,b,c,d){ console.log(a+'\t'+b+'\t'+c+'\t'+d); return b;}) //123<%1%> 1 0 <%1%><%2%><%3%> <%2%> 2 5 <%1%><%2%><%3%> <%3%> 3 10 <%1%><%2%><%3%> 根据这种参数replace可以实现很多强大的功能,尤其是在复杂的字符串替换语句中经常使用。
strObj.split(regObj)
我们经常使用split方法把字符串分割为字符数组
'a,b,c,d'.split(','); //["a", "b", "c", "d"] 和replace方法类似,在一些复杂的分割情况下我们可以使用正则表达式解决
'a1b2c3d'.split(/\d/); //["a", "b", "c", "d"]
这样就可以按照数字分割字符串了,是不是很强大。看完这两篇博客基本就能对平时用到的JavaScript正则表达式游刃有余了。要求在前端把一个div中的英文段落单词首字母都换成大写,你是不是知道该怎么做了?